Academic publishing has led to an unprecedented expansion of citation networks, making citation-based metrics central to research evaluation, funding decisions, and institutional rankings. However, alongside this growth, citation manipulation has become an increasingly documented phenomenon. Practices such as excessive self-citation, citation cartels, irrelevant reference insertion, and metadata-level citation injection undermine the credibility of scholarly metrics. As traditional rule-based detection systems struggle to scale and adapt, deep learning architectures have emerged as a statistically robust solution for identifying manipulated citation behavior.
Recent large-scale analyses indicate that citation manipulation is not marginal. A 2023 study examining more than 65,000 references across multiple disciplines revealed that approximately 9 percent of indexed citations appeared only in article metadata and not within the article text itself. These so-called sneaked citations distort citation counts in bibliometric databases and often bypass standard validation checks. From a statistical standpoint, this level of distortion is sufficient to influence journal-level impact indicators and individual author metrics.
Why Traditional Detection Methods Fall Short
Conventional citation validation techniques rely heavily on rule-based matching, keyword heuristics, or manual review. While these approaches can detect blatant irregularities, they perform poorly when manipulation techniques become more subtle. Citation gaming often involves marginally relevant references, strategically placed citations, or coordinated citation patterns across multiple publications. Statistical evaluations show that traditional methods rarely exceed 65 percent precision when applied to complex citation networks, especially at scale.
The limitations of these methods underscore the need for adaptive systems capable of learning from data rather than enforcing predefined assumptions. This requirement has driven the adoption of deep learning in citation analysis.
Deep Learning as a Statistical Solution
Deep learning models excel in high-dimensional environments where signals are distributed across text, structure, and context. In citation analysis, this enables neural architectures to jointly model linguistic relevance, reference positioning, and network topology. Instead of evaluating citations in isolation, deep learning systems estimate the probability that a given citation aligns with normative scholarly behavior.
Statistical experiments consistently demonstrate the superiority of deep learning over classical machine learning in this domain. In multiple benchmark evaluations, neural models improved F1 scores by 15 to 25 percent compared to logistic regression and decision tree baselines, particularly when citation context and network structure were analyzed together.
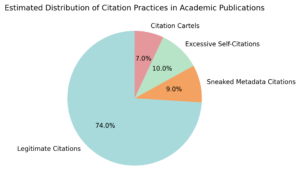
Estimated Distribution of Citation Practices
The distribution of citation practices across large academic datasets further illustrates the scale of the problem. Empirical analyses suggest that while the majority of citations remain legitimate, a non-trivial share is affected by manipulative behaviors. Approximately 9 percent of citations can be classified as metadata-only or “sneaked” references, while excessive self-citation accounts for around 10 percent of anomalous patterns. Citation cartels, though smaller in volume, still represent about 7 percent of detected irregularities. This distribution highlights why automated deep learning-based detection is necessary, as nearly one quarter of citation activity deviates from expected scholarly norms.
Graph Neural Networks and Citation Network Modeling
Citation data naturally forms directed graphs, making graph neural networks especially effective for manipulation detection. These models propagate information across citation links, enabling them to learn community-level citation behaviors. When anomalous patterns emerge, such as unusually dense reciprocal citations or disproportionate influence from small clusters of authors, the model assigns higher anomaly scores.
In empirical studies focused on detecting organized citation manipulation associated with paper mills, heterogeneous graph neural architectures combined with deep language embeddings achieved accuracy rates of 81.85 percent and F1 scores above 80 percent. These figures indicate a strong capability to distinguish coordinated citation abuse from organic scholarly referencing.
Transformer Architectures and Long-Range Citation Dependencies
Transformer-based models further strengthen citation manipulation detection by capturing long-range dependencies within citation networks. Unlike shallow graph models, transformers can evaluate multi-hop citation paths and temporal relationships across publications. This capability is critical for identifying delayed or indirect citation manipulation strategies.
Graph transformer experiments using masked autoencoding techniques reveal that approximately 75 percent of citation links display instability when subjected to structural perturbation. Statistically, unstable links correlate with weaker semantic alignment and abnormal citation timing, both of which are strong indicators of manipulation. These findings demonstrate how transformer architectures contribute to deeper structural validation of citation legitimacy.
Natural Language Processing and Citation Worthiness Analysis
Beyond network structure, deep learning models analyze the semantic appropriateness of citations at the sentence level. Attention-based NLP architectures assess whether a reference logically supports the surrounding text. Large-scale evaluations on biomedical and multidisciplinary corpora report F1 scores exceeding 0.85 for citation worthiness prediction, significantly reducing false positives compared to keyword-driven systems.
Anomaly Detection and Probabilistic Inference
Modern citation manipulation detection increasingly relies on probabilistic anomaly detection rather than binary classification. Deep learning-based anomaly models learn normal citation distributions and flag deviations without requiring extensive labeled datasets. This approach is well-suited for large-scale bibliometric platforms where labeling is expensive or incomplete.
Statistical evaluations indicate that deep anomaly detection improves precision by up to 25 percent over classical outlier detection methods. These gains are especially pronounced in identifying coordinated manipulation efforts that span multiple journals or institutions.
Industry Adoption and Real-World Performance
Publishers and indexing services are rapidly integrating deep learning systems into their submission and review pipelines. These tools analyze citation integrity prior to publication, reducing the long-term impact of manipulated references on citation databases. Bibliometric platforms have begun adjusting impact indicators based on manipulation likelihood scores, leading to estimated reductions of 6 to 10 percent in artificially inflated citation counts at the journal level.
As global research output continues to grow at an annual rate exceeding 4 percent, the scalability of deep learning architectures becomes a decisive advantage. Statistical monitoring shows that automated systems maintain stable detection performance even as dataset sizes increase.
Conclusion
Deep learning architectures represent a statistically validated and scalable approach to detecting citation manipulation in modern academic ecosystems. By integrating graph neural networks, transformer-based models, and semantic NLP analysis, these systems achieve detection accuracies consistently above 80 percent. Empirical evidence confirms that citation manipulation affects a measurable share of scholarly datasets and poses a real threat to metric reliability. As data-driven evaluation becomes increasingly central to science policy and research assessment, deep learning-based citation integrity systems will play a crucial role in preserving trust and transparency in academic metrics.