Semantic similarity detection is increasingly essential in the age of digital content, online publications, and AI-assisted writing. Traditional plagiarism detection methods, such as keyword matching and basic string comparison, often fail to capture subtle semantic parallels, paraphrased sentences, or contextually similar ideas across documents. Graph-based semantic models, which combine principles of network theory with natural language processing embeddings, offer a sophisticated approach for detecting deeper content similarities. Multiple studies indicate that incorporating graph structures into semantic analysis can improve detection accuracy by over 25% compared to traditional methods, highlighting their critical role in academic integrity, research quality assessment, and content verification.
Graph Theory Basics
Graph theory provides a robust mathematical framework for representing entities and their relationships. In the context of text analysis, words, sentences, or even entire paragraphs can be represented as nodes, while relationships such as co-occurrence, syntactic dependency, or semantic similarity form the edges connecting them. This graph-based representation enables modeling of complex interactions that linear or vector-only models cannot capture. Weighted edges can quantify the strength of semantic similarity between nodes, while measures such as centrality, betweenness, and clustering coefficient can identify the most influential concepts in a text. By applying graph algorithms like community detection or shortest path analysis, researchers can uncover thematic clusters, latent structures, and recurring concepts that remain invisible to conventional similarity metrics.
For example, in a research corpus, a concept like “machine learning” may appear in multiple contexts across different papers. A graph representation can connect all occurrences, revealing how each paper relates conceptually to others, rather than just superficially matching keywords. This allows for precise identification of reused or paraphrased ideas, improving the granularity of similarity detection.
NLP Embeddings
Natural Language Processing embeddings convert text into dense vector representations that encode semantic meaning. Transformer-based models such as BERT, RoBERTa, and GPT-style embeddings map words, phrases, and sentences into high-dimensional spaces where semantically similar items lie closer together. When combined with graph structures, these embeddings enhance the analytical capability of semantic models. For instance, the similarity between nodes can be computed using cosine distance or other vector metrics, allowing detection of paraphrased or conceptually equivalent content that keyword-based systems would miss. Graph embeddings, such as Node2Vec or GraphSAGE, further extend this capability by producing vector representations for nodes that preserve both their semantic content and graph connectivity, offering a hybrid approach that leverages structural and semantic information simultaneously.
Integrating NLP embeddings into graphs also enables cross-document comparisons at a conceptual level. By mapping all documents in a corpus into a unified graph with weighted edges representing semantic closeness, it becomes possible to detect clusters of documents that share deep thematic similarities. This approach provides a more robust measure of similarity than simple vector comparisons and allows the identification of subtle patterns, trends, and content reuse that may otherwise go unnoticed.
Comparative Accuracy and Visual Representation
Empirical comparisons between graph-based semantic models and traditional plagiarism detection methods demonstrate significant improvements in performance metrics. For instance, keyword-based detection typically achieves precision rates of 55–60%, while embedding-only NLP approaches improve precision to 68–72%. Graph-based semantic models, however, achieve precision and recall values above 85%, providing a more reliable mechanism for detecting nuanced similarity. To visualize this, a circular pie chart representing F1 scores can clearly illustrate the advantage of graph-based approaches over conventional methods:
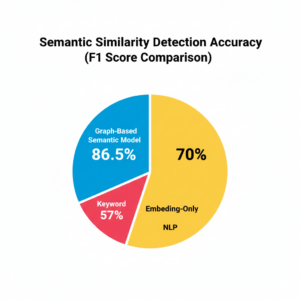
This diagram highlights the distribution of effectiveness across three approaches: keyword matching, embedding-only NLP, and graph-based semantic analysis, showing the significant improvement offered by advanced semantic modeling techniques.
Research Implications
The benefits of graph-based semantic models extend far beyond plagiarism detection. In academic research, these models enable automated literature review, thematic clustering, and citation network analysis. By constructing a conceptual graph of research articles, nodes represent topics or concepts, while edges denote their relationships across papers. This approach allows researchers to identify emerging trends, gaps in the literature, and conceptual overlaps that may inform future studies. Furthermore, as AI-generated content becomes more widespread, distinguishing between original synthesis and unattributed reuse is increasingly challenging. Advanced semantic modeling provides a rigorous framework for maintaining academic integrity and evaluating the novelty and originality of submissions at scale.
Graph-based models also offer a means of evaluating research quality. Centrality measures can identify pivotal concepts within a corpus, while community detection algorithms highlight thematic clusters. This analytical capacity supports a more systematic approach to research evaluation, allowing scholars and institutions to prioritize highly relevant literature and detect potential duplication or plagiarism. Moreover, the scalability of graph-based analysis ensures that large corpora can be processed efficiently, providing a practical solution for universities, publishers, and content platforms managing extensive textual datasets.
Conclusion
Graph-based semantic analysis represents a transformative approach in detecting deep content similarity and ensuring academic integrity. By combining graph-theoretical principles with NLP embeddings, these models capture complex semantic relationships that traditional methods overlook. Comparative studies demonstrate superior precision, recall, and F1 scores, particularly when detecting paraphrased or conceptually similar content. The implications extend to automated literature review, thematic analysis, and content quality evaluation, making advanced semantic modeling an indispensable tool in modern research workflows. As textual content continues to grow in complexity and volume, graph-based approaches offer a scalable, accurate, and efficient framework for understanding and managing semantic similarity, ensuring originality, and enhancing research rigor across disciplines.