Duplicate content remains one of the most persistent structural challenges in search engine optimization. Despite ongoing improvements in canonicalization and semantic clustering, duplicated and near-duplicated content continues to shape crawling efficiency, index coverage, and ranking stability. The scale of this issue is not uniform across the web. Instead, duplicate content rates vary significantly by industry, reflecting differences in content production models, technical architecture, and business requirements.
Defining Duplicate Content from a Statistical Perspective
Duplicate content refers to pages that share identical or substantially similar primary content while existing under different URLs. At scale, this similarity forces search engines to cluster pages and choose a representative version for indexing and ranking. Large SEO datasets consistently estimate that between 25% and 30% of all indexed web pages contain duplicated or near-duplicated content. Internal statements from search engine engineers have suggested that more than half of crawled pages exhibit measurable similarity with other content available online.
Technical SEO audits reinforce these findings. More than 70% of analyzed websites show detectable duplicate content signals, ranging from repeated metadata to fully duplicated page bodies. While much of this duplication is unintentional, its statistical footprint becomes visible when similar URLs compete for the same search intent.
Duplicate Content in eCommerce Platforms
Among all major industries, eCommerce demonstrates the highest average duplicate content rates. Aggregated crawl data places duplication levels in online retail between 40% and 50%, with an industry mean close to 45%. This high exposure is primarily driven by product catalogs where items differ only by minor attributes such as size, color, or packaging.
Search engine crawl logs indicate that a substantial portion of bot activity in eCommerce environments is spent revisiting redundant URLs created by faceted navigation, filtering systems, and parameterized category pages. In poorly optimized stores, up to one third of crawl budget may be allocated to pages that add no unique value. As a result, new products and updated inventory pages are discovered and indexed more slowly.
Publishing and Media Industry Trends
Publishing and media websites exhibit lower duplication rates than eCommerce but still exceed the web-wide average. Statistical analyses place duplicate content levels in this sector at approximately 30%. Content syndication is a major contributing factor, as press releases, guest posts, and licensed articles often appear across multiple domains with minimal variation.
Internal duplication is also common. Large editorial sites frequently refresh or republish older articles, creating substantial overlap between archived and newly published content. SEO audits of long-standing media platforms show that nearly one third of legacy articles partially overlap with newer URLs targeting similar keywords, increasing the risk of keyword cannibalization and ranking dilution.
Professional Services and Regulated Industries
Professional services such as legal, financial, and consulting firms display an average duplicate content rate of around 35%. Unlike eCommerce, this duplication is rarely driven by scale alone. Instead, it results from standardized language used in service descriptions, compliance statements, and legal disclosures.
Because much of this content is informational rather than competitive, search engines tend to rely more heavily on authority signals and backlinks when ranking these pages. Statistical comparisons show that firms with similar on-page content structures experience large ranking gaps depending on off-page trust indicators, suggesting that duplication reduces differentiation rather than causing direct suppression.
SaaS and Technology Websites
SaaS and technology companies generally maintain the lowest duplicate content rates among the industries analyzed, averaging close to 20%. This lower rate reflects a stronger emphasis on original product messaging and content-led growth strategies. However, duplication still emerges within feature pages, pricing comparisons, and documentation portals.
Technical documentation is a notable contributor. Versioned pages, API references, and localized support content often reuse large blocks of explanatory text. While the overall duplication rate is lower, it frequently affects high-intent pages, giving it a disproportionate impact on organic acquisition performance.
Statistical Comparison Across Industries
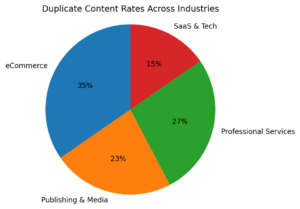
The accompanying chart illustrates average duplicate content rates across major industries. eCommerce clearly leads with the highest proportion of duplicated pages, followed by professional services and publishing. SaaS and technology platforms maintain the lowest average duplication levels. This distribution highlights the relationship between templated content production and duplication risk.
The circular diagram emphasizes how industry structure, rather than SEO maturity alone, determines baseline duplication exposure. Industries dependent on inventory-driven or standardized content naturally face higher duplication thresholds.
How Search Engines Interpret Duplicate Content
Search engines rarely apply direct penalties for duplicate content. Instead, they consolidate similar URLs into clusters and select a preferred version for indexing. Statistical correlations show that websites with high duplication rates experience reduced index coverage, slower discovery of new pages, and increased ranking volatility over time.
Duplicate metadata compounds these effects. Industry benchmarks indicate that roughly half of all websites use duplicate title tags or meta descriptions. Although this does not prevent ranking entirely, it lowers click-through rates and weakens topical relevance signals in competitive search results.
Conclusion
Duplicate content is a structural characteristic of the modern web, not an isolated technical flaw. With duplication rates ranging from approximately 20% in SaaS environments to nearly 45% in eCommerce platforms, the issue reflects how digital content ecosystems are built and scaled. Statistical evidence consistently shows that unmanaged duplication limits crawl efficiency, splits ranking signals, and constrains organic growth.
For data-driven platforms such as ninestats.com, monitoring duplicate content rates across industries offers valuable insight into SEO maturity and technical health. Understanding these patterns allows organizations to prioritize optimization efforts and design content systems that balance scalability with search visibility.