By 2026, content quality has become one of the most critically evaluated factors across digital publishing, academic research, and search engine optimization. The rapid expansion of online content, combined with the widespread use of generative artificial intelligence, has forced platforms and institutions to redefine how quality is measured. Similarity and plagiarism statistics now function as central signals used to evaluate originality, trust, and informational value rather than simple compliance metrics.
Automated quality assessment systems have become essential in an environment where content production far exceeds the capacity of manual review. Similarity analysis and plagiarism detection have evolved into sophisticated mechanisms capable of semantic comparison, contextual evaluation, and pattern recognition across massive datasets.
The Role of Similarity in Modern Quality Evaluation
Similarity is no longer assessed through exact phrase matching alone. Modern detection systems analyze meaning, structure, and contextual alignment to determine whether a text offers genuine contribution or merely reproduces existing narratives. In 2026, similarity itself is not treated as inherently negative, but excessive overlap without added insight is widely interpreted as a sign of low-value content.
Statistical evaluations of indexed web pages demonstrate that content with similarity levels exceeding thirty percent relative to existing high-performing pages shows significantly reduced ranking stability. This indicates that similarity metrics now operate as quality filters rather than secondary diagnostics within search algorithms.
Plagiarism Statistics as Indicators of Trust
Plagiarism remains one of the most visible indicators of compromised content credibility. Global studies conducted between 2024 and 2025 showed that nearly one third of student submissions contained unattributed borrowed material. In commercial and editorial publishing, audits revealed that over twenty percent of articles reused existing content with minimal transformation.
In 2026, plagiarism is evaluated through a more nuanced lens. Detection systems differentiate between deliberate copying, improper citation, and structural overlap caused by standardized terminology or AI-assisted drafting. This contextual interpretation allows institutions and publishers to focus on improving quality rather than relying solely on punitive thresholds.
Distribution of Similarity Levels in Digital Content (2026)
The diagram below illustrates the distribution of digital content based on similarity levels, reflecting aggregated industry data from publishing, SEO, and academic review environments.
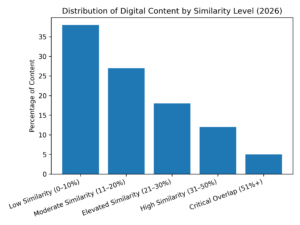
The data shows that while a substantial portion of content maintains low similarity, nearly one third falls into elevated ranges requiring editorial attention. Content within the highest similarity brackets consistently correlates with reduced visibility, lower engagement, and diminished trust signals.
The Influence of AI on Similarity Metrics
Generative AI has reshaped content production at scale. By the end of 2025, more than half of all newly published online content was created with some level of AI assistance. While this shift has increased efficiency, it has also intensified similarity challenges, as AI models tend to reproduce dominant linguistic patterns found in training data.
As a result, content quality evaluation in 2026 places less emphasis on whether AI was used and more on whether human expertise introduced differentiation, depth, and contextual relevance. Content generated without editorial refinement is more likely to exhibit elevated similarity and underperform in competitive environments.
Similarity Thresholds and Quality Expectations
Industry benchmarks indicate that acceptable similarity thresholds have tightened. Academic journals increasingly flag manuscripts with similarity scores above fifteen percent for manual review, while SEO-focused platforms report limited success for pages exceeding twenty percent similarity compared to existing top results.
These thresholds reflect a broader expectation that published content should extend existing knowledge rather than restate it. Contextual evaluation has therefore become central to interpreting similarity data accurately.
Search Visibility, Authority, and User Trust
Search engines increasingly treat similarity and plagiarism metrics as proxies for authority and usefulness. Original content demonstrates stronger engagement indicators, including longer session duration and higher interaction rates. These behavioral signals reinforce algorithmic trust and ranking stability over time.
Conversely, content created through aggregation or superficial rewriting struggles to maintain visibility even when technically optimized. Original insight and experiential depth remain the strongest differentiators in saturated content environments.
Academic Integrity and Educational Perspectives
Within education, plagiarism statistics remain fundamental to integrity frameworks, but institutions increasingly avoid rigid reliance on similarity percentages alone. Research shows that transparent similarity reports combined with instructional feedback reduce repeated violations and improve citation practices.
This approach aligns similarity analysis with learning outcomes rather than enforcement alone, reflecting a broader shift toward quality-driven assessment models.
Conclusion: Originality as the Core Quality Signal
In 2026, similarity and plagiarism statistics represent foundational content quality signals rather than peripheral checks. They influence ranking algorithms, editorial standards, and academic evaluation while shaping audience trust and engagement.
As detection technologies continue to advance, superficial originality is no longer sufficient. True content quality is defined by contribution, interpretation, and insight. Content creators who treat similarity metrics as strategic guidance rather than obstacles are best positioned to succeed in the evolving digital ecosystem.